Intro to Divide and Conquer Paradigm

Safiul Kabir is a Lead Software Engineer at Cefalo. He specializes in full-stack development with Python, JavaScript, Rust, and DevOps tools.
In computer science, divide and conquer is an algorithm design paradigm. An algorithmic paradigm or algorithm design paradigm is a generic model or framework which underlies the design of a class of algorithms. An algorithmic paradigm is an abstraction higher than the notion of an algorithm, just as an algorithm is an abstraction higher than a computer program.
List of well-known paradigms:
Backtracking
Branch and bound
Brute-force search
Divide and conquer
Dynamic programming
Greedy algorithm
Recursion
Prune and search
Divide and Conquer
The divide-and-conquer paradigm is often used to find an optimal solution to a problem. Its basic idea is to decompose a given problem into two or more similar, but simpler, subproblems, to solve them in turn, and to compose their solutions to solve the given problem. Problems of sufficient simplicity are solved directly.
The divide-and-conquer technique is the basis of efficient algorithms for many problems, such as sorting (e.g., quicksort, merge sort), multiplying large numbers (e.g., the Karatsuba algorithm), finding the closest pair of points, syntactic analysis (e.g., top-down parsers), and computing the discrete Fourier transform (FFT).
How do Divide and Conquer Algorithms Work?
Here are the steps involved:
Divide: Divide the given problem into sub-problems of the same or related type using recursion until the sub-problem is simple enough to be solved directly.
Conquer: When the subproblem is simple enough, solve it directly.
Combine: Combine the solutions of the sub-problems that are part of the recursive process to solve the actual problem.
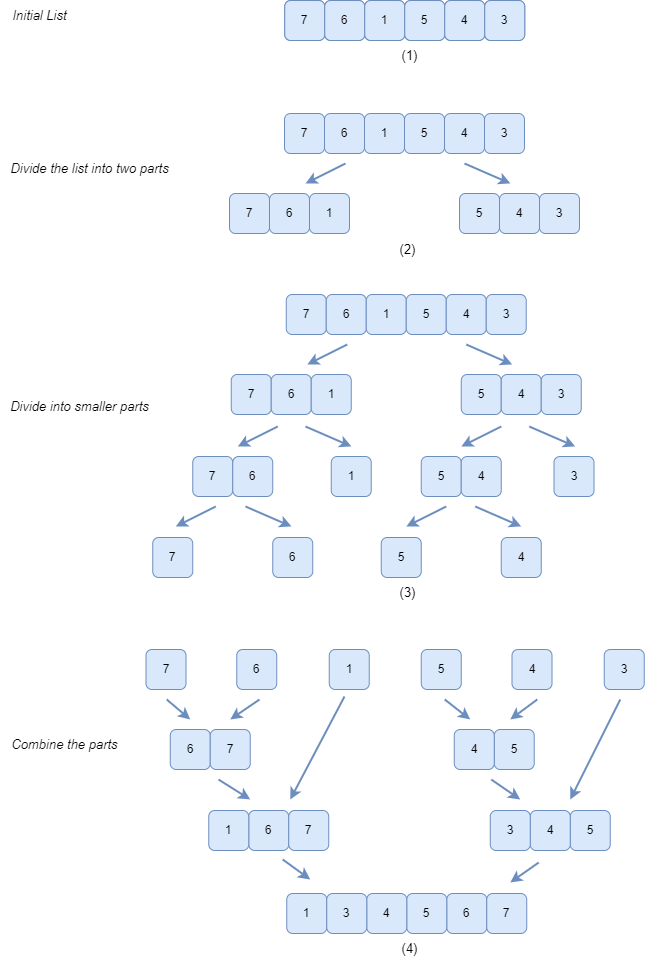
For example, to sort a given list of n natural numbers, split it into two lists of about n/2 numbers each, sort each of them in turn, and interleave both results appropriately to obtain the sorted version of the given list. This approach is known as the merge sort algorithm.
Let's visualize this concept with the help of an example:
Time Complexity
The complexity of the divide and conquer algorithm is calculated using the master theorem.
T(n) = aT(n/b) + f(n),
where,
n = size of input
a = number of subproblems in the recursion
n/b = size of each subproblem. All subproblems are assumed to have the same size.
f(n) = cost of the work done outside the recursive call, which includes the cost of dividing the problem and cost of merging the solutions
Let us take an example to find the time complexity of a recursive problem.
For a merge sort, the equation can be written as:
T(n) = aT(n/b) + f(n)
= 2T(n/2) + O(n)
Where,
a = 2 (each time, a problem is divided into 2 subproblems)
n/b = n/2 (size of each sub problem is half of the input)
f(n) = time taken to divide the problem and merging the subproblems
T(n/2) = O(n log n) (To understand this, please refer to the master theorem.)
Now, T(n) = 2T(n log n) + O(n)
≈ O(n log n)
Is Binary Search a Divide and Conquer Algorithm?
The name "divide and conquer" is sometimes applied to algorithms that reduce each problem to only one sub-problem, such as the binary search algorithm for finding a record in a sorted list (or its analogue in numerical computing, the bisection algorithm for root finding). These algorithms can be implemented more efficiently than general divide-and-conquer algorithms; in particular, if they use tail recursion, they can be converted into simple loops. Under this broad definition, however, every algorithm that uses recursion or loops could be regarded as a "divide-and-conquer algorithm". Therefore, some authors consider that the name "divide and conquer" should be used only when each problem may generate two or more subproblems. The name decrease and conquer has been proposed instead for the single-subproblem class, such as the binary search.
Divide and Conquer Vs Dynamic Programming approach
The divide and conquer approach divides a problem into smaller subproblems; these subproblems are further solved recursively. The result of each subproblem is not stored for future reference, whereas, in a dynamic approach, the result of each subproblem is stored for future reference.
Use the divide and conquer approach when the same subproblem is not solved multiple times. Use the dynamic approach when the result of a subproblem is to be used multiple times in the future.
Let us understand this with an example. Suppose we are trying to find the Fibonacci series.
Divide and Conquer approach:
fib(n):
If n < 2: return 1
Else: return f(n - 1) + f(n -2)
Dynamic Programming approach:
mem = []
fib(n):
If n in mem: return mem[n]
else:
If n < 2: f = 1
else: f = f(n - 1) + f(n -2)
mem[n] = f
return f
In the dynamic programming approach, mem stores the result of each subproblem.
Advantages of Divide and Conquer Algorithm
The complexity for the multiplication of two matrices using the naive method is O(n3), whereas using the divide and conquer approach (i.e. Strassen's matrix multiplication) is O(n2.8074). This approach also simplifies other problems, such as the Tower of Hanoi.
Divide-and-conquer algorithms are naturally adapted for execution in multi-processor machines, especially shared-memory systems where the communication of data between processors does not need to be planned in advance because distinct sub-problems can be executed on different processors.
Divide-and-conquer algorithms naturally tend to make efficient use of memory caches. The reason is that once a sub-problem is small enough, it and all its sub-problems can, in principle, be solved within the cache, without accessing the slower main memory.
In computations with rounded arithmetic, e.g. with floating-point numbers, a divide-and-conquer algorithm may yield more accurate results than a superficially equivalent iterative method. For example, one can add N numbers either by a simple loop that adds each datum to a single variable, or by a D&C algorithm called pairwise summation that breaks the data set into two halves, recursively computes the sum of each half, and then adds the two sums. While the second method performs the same number of additions as the first and pays the overhead of the recursive calls, it is usually more accurate.
Implementation Challenges
Divide-and-conquer algorithms are naturally implemented as recursive procedures. In that case, the partial sub-problems leading to the one currently being solved are automatically stored in the procedure call stack.
In recursive implementations of D&C algorithms, one must make sure that there is sufficient memory allocated for the recursion stack, otherwise, the execution may fail because of stack overflow. Stack overflow may be difficult to avoid when using recursive procedures since many compilers assume that the recursion stack is a contiguous area of memory, and some allocate a fixed amount of space for it.
In any recursive algorithm, there is considerable freedom in the choice of the base cases, the small subproblems that are solved directly in order to terminate the recursion. Choosing the smallest or simplest possible base cases is more elegant and usually leads to simpler programs because there are fewer cases to consider and they are easier to solve.
For some problems, the branched recursion may end up evaluating the same sub-problem many times over. In such cases, it may be worth identifying and saving the solutions to these overlapping subproblems, a technique which is commonly known as memoization. Followed to the limit, it leads to bottom-up divide-and-conquer algorithms such as dynamic programming.



